As we mentioned in our first article about the pros and cons of serverless architectures, if you work with stateless cloud functions, you often need to adopt a new paradigm of thinking. For example, distributed locking becomes an important problem much sooner than in a traditional stateful context.
For services with low-to-moderate levels of traffic, a single stateful server can use the Operating System’s synchronization mechanisms to solve for race conditions. With Serverless Functions however, each request is usually handled by a different instance, meaning that locking has to happen at a different level. In this blog post, we will share Throne’s solution using Firestore’s transactions feature.
The problem
Race conditions and odd behavior due to parallel executions.
Throne handles thousands, sometimes tens of thousands of orders per day. Tens of thousands of orders turn into hundreds of thousands of webhooks from the shop systems and external providers we integrate with. Often these webhooks are sent in quick succession and, combined with our webhook reconciliation logic, can lead to ten different processes that want to propagate updates to a single order at the same time.
Without synchronization across function executions, we would quickly end up in a situation where an item that was in an ordered status at the beginning of the execution might end up being in a shipped status towards the middle of the execution, due to it being concurrently updated in a different process.
Solution 1: max_instances = 1
A naive approach to force sequential execution would be to limit your cloud function to a maximum of one instance. If using Google Cloud Functions v2 you would also need to disable concurrency for this to work. Now, at any one time you will only have one function instance handling one request, ensuring sequential execution.
Success, right?

Sure, but this architecture won’t scale to even a modest level of traffic, which will manifest as:
✅No race conditions, since processing happens sequentially
❌Increased latency due to only one request being handled by the system at a time
❌Webhooks being dropped due to no instance being allocated in a reasonable timeframe
Solution 2: Using PubSub to trigger a max_instances=1 function
To solve the scaling problem of our first idea, we instead allow many instances to accept the incoming requests, but only one instance to process them. This is a pattern we use in cases where latency isn’t critical, such as sending out Discord notifications without exceeding a global rate-limit.
Basically, you take the function from our first section, and split it into two separate functions: one for handling the incoming webhook, and one for processing the requests. The webhook function only receives the incoming request and uses Google PubSub to trigger the processing function.
The processing function has max_instances = 1 set, and subscribes to the PubSub topic. The PubSub system therefore implements a queue for the processing work to be done sequentially.
Okay, so this solves the problem of scalably responding to webhooks, and the processing happens sequentially so there is no risk of races. But what about cases where the processing needs to happen with low latency, such as when responding to a user’s request?
✅No race conditions, since processing happens sequentially
✅No dropping of webhooks, since they can still be handled concurrently
❌Slow processing since this happens sequentially
Solution 3: serverless locking system
Not only do we want sequential executions, we also want maximal parallelization of requests that don’t work on the same entities. If five webhooks come in, two for order A (call them RA1 and RA2) and three for order B (call them RB1, RB2 and RB3), we want RA1 to execute before RA2 but in parallel to RB1.
This brought us to our final solution of a locking system.
import * as admin from "firebase-admin";
export const EXPIRE_LOCK_TIME = 1000 * 60 * 10; // 10 minutes
export const DEFAULT_LOCK_TIMEOUT = 30_000;
admin.initializeApp({
// ...
});
db = admin.firestore();
export class LockRepository {
private getRef(key: string): DBRef<LockRecord> {
return db.collection(DatabaseModel.Locks.key).doc(key).withConverter(new Converter<LockRecord>());
}
public async get(key: string, transaction: FirebaseFirestore.Transaction): Promise<LockRecord> {
const ref = this.getRef(key);
return transaction.get(ref).then((d) => d.data());
}
public async release(key: string): Promise<void> {
const ref = this.getRef(key);
await ref.update({ isLocked: false });
}
public async acquire(key: string, transaction: FirebaseFirestore.Transaction): Promise<void> {
const ref = this.getRef(key);
const updates: LockRecord = {
isLocked: true,
expireLockAt: Date.now() + EXPIRE_LOCK_TIME,
lockedAt: Date.now(),
key,
};
transaction.set(ref, updates);
}
public async runTransaction<T>(callback: (transaction: FirebaseFirestore.Transaction) => Promise<T>): Promise<T> {
return db.runTransaction<T>(async (transaction) => {
return callback(transaction);
});
}
}
export class Locker {
private lockRepository: LockRepository;
private timeout: number;
public constructor(lockRepository: LockRepository, timeout: number = DEFAULT_LOCK_TIMEOUT) {
this.lockRepository = lockRepository;
this.timeout = timeout;
}
public async runWithLock<T>(key: string, cb: () => Promise<T>): Promise<T> {
const acquiredLock = await this.acquire(key);
if (!acquiredLock) {
// Could not acquire lock
throw new ThroneError("Could not acquire lock");
}
let resp: T;
try {
resp = await cb();
} finally {
await this.lockRepository.release(key);
}
return resp;
}
private async acquire(key: string): Promise<boolean> {
// Timeout
const startTime = Date.now();
// Start transaction
let lockAcquired = false;
while (!lockAcquired) {
const timePassed = Date.now() - startTime;
if (timePassed > this.timeout) {
// Timeout
break;
}
lockAcquired = await this.lockRepository.runTransaction(async (transaction) => {
// Init
let canAcquireLock = false;
// Get lock record
const lockRecord = await this.lockRepository.get(key, transaction);
// If lock record is not locked, we can acquire lock
if (lockRecord?.isLocked !== true) {
// Can acquire lock
canAcquireLock = true;
} else {
// Lock record is locked
if (lockRecord?.expireLockAt && lockRecord.expireLockAt < Date.now()) {
// Can acquire lock
canAcquireLock = true;
}
}
if (!canAcquireLock) return false;
// Acquire lock
await this.lockRepository.acquire(key, transaction);
return true;
});
// Wait one second
await wait(1000);
}
// Return
return lockAcquired;
}
}
The system leverages an eager waiting lock system using database transactions. Each process can decide on its own lock key for its own use case, making the system flexible.
So what actually happens in our above example?
Let’s suppose RA1, RA2, RB1, RB2, RB3 arrive at our endpoint. This would spin up 5 instances, call them IA1, IA2, … IB3.
RA1 acquires the lock first. RA1 would start to execute, updating order A. During the time RA1 is being processed, RA2 would be eagerly waiting for the lock to be released. Once the lock is released and RA1 is complete, RA2 will start executing the business logic. As you can see the requests are handled sequentially.
While RA1 is being executed, the requests for order B would start processing. Let’s assume RB1 acquires the lock for order B first. It would execute, then letting RB2 acquire the lock and then RB3, once RB2 is done.
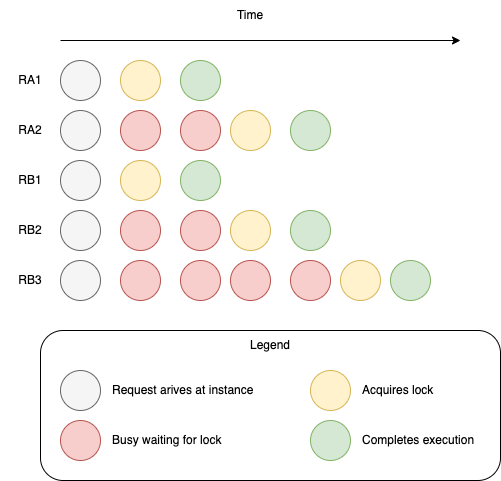
✅No race conditions, since the critical section gets processed sequentially
✅Scalable since everything except the critical section happens concurrently
Conclusion
Serverless functions have many advantages but have a few gotchas that require creative solutions. Synchronizing concurrent updates is one of the examples where a simpler solution exists for traditional serverful architectures. This article shows a flexible and reusable method you can use to achieve sequential execution for processes working on the same entities while still allowing parallel execution for processes working on different properties.
I hope it helps!
If you found this interesting or have questions, check us out at throne.me or pop me an email at lenny@jointhrone.com
