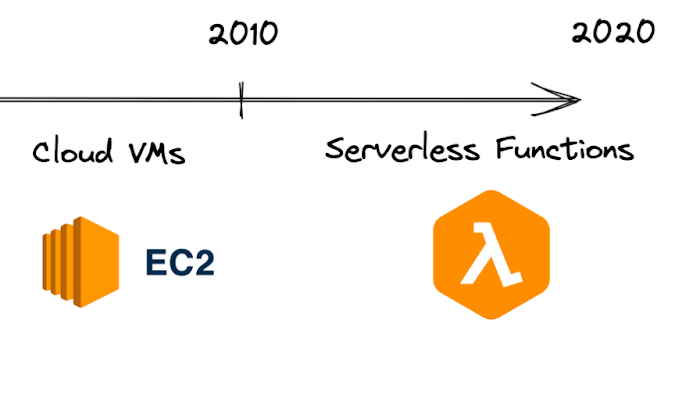
Having recently made the jump from Google to a trendy startup with a trendy tech-stack, I often find myself evaluating the merits of my trendy new tools. Sometimes the marketing materials are so full of platitudes like scalability and flexibility that it’s hard to understand what a term like Serverless Architecture even means. While serverless databases are relatively mature by now, Serverless Functions (AWS Lambda, Google Cloud Function etc) have significant functionality and tooling gaps by which they make it felt that they are still early. So what do we actually have to gain and/or lose by banishing servers from our architectures?

tl;dr
✅ Reduced costs (probably)
✅ Iteration speed and learning curve
❌ Cold starts
❌ No async works
❌ No long-running tasks
❌ New statelessness design paradigms
The Benefits
Free lunch! The cost paradox
At Throne, we serve seven-figures of monthly page-views with a four-figure USD cloud bill. Other companies we’ve talked to are paying an order of magnitude more for a comparable amount of traffic.
While it’s intuitive that we can save developer-time by allowing our cloud-providers to handle more of our infrastructure, it’s kind of surprising that we might actually save on server costs by doing so. Consider the following progression of hosting solutions over the years:
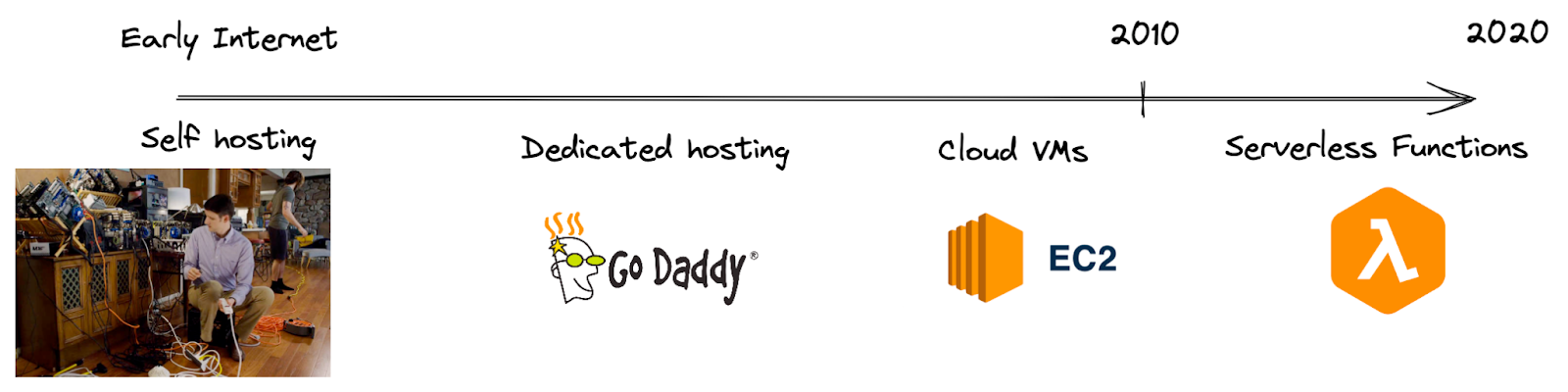
One might naively make the following analogy:

Although in both cases we are paying to outsource labor that would otherwise be performed in-house, the economies of scale lead to very different outcomes. The restaurants in the cloud-computing analogy are serving millions of meals per day, and the raw ingredients (cpu-seconds) for the DIYers are only available in bulk.
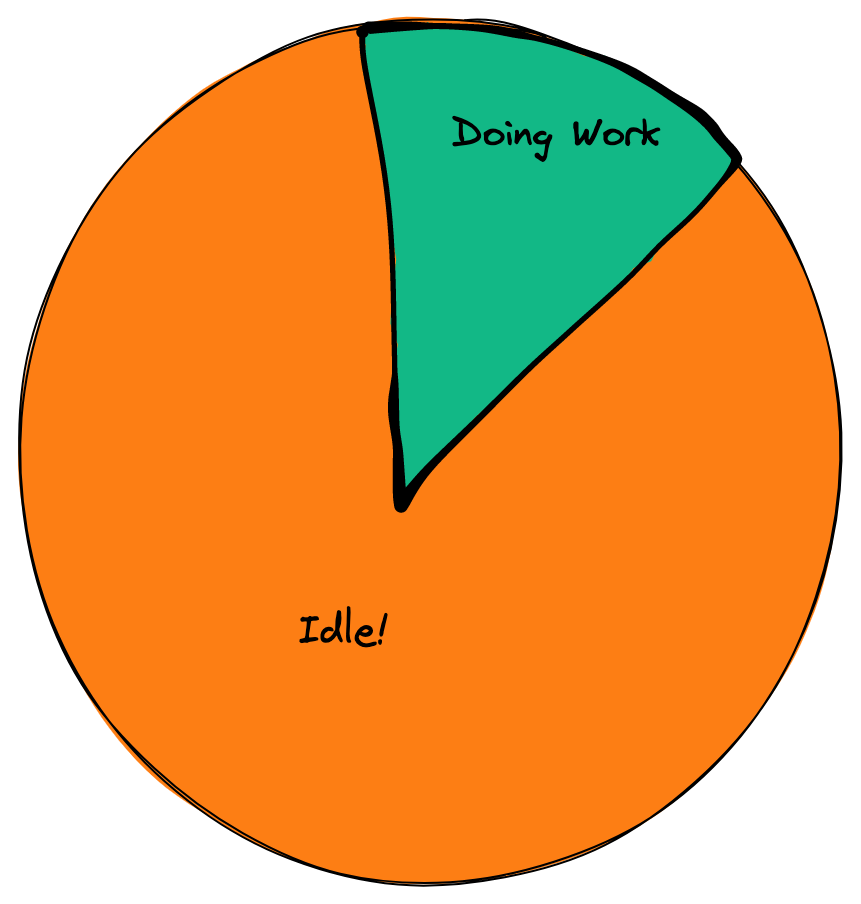
For example, take a workload that polls an external API to sync some data every minute. If we were renting a VM, we wouldn’t turn it off between polls. If the poll takes six seconds, and we need to do it every minute, then we are still paying for 54 seconds of idle time, an overpayment by a factor of 9. Even if a serverless cpu-second costs three times more, you come out well ahead. This may be a hand-picked example, but similar savings exist for other workloads (e.g. due to traffic fluctuations for web servers).
Ergonomics (vs what Google engineers are using)
When I joined Throne, the dev team was amused to learn that I didn’t know how to use git. Google has a lot of in-house tooling, some of which is better (version control, build, data pipelines) and some which is worse (IDE, frontend libraries) than its public counterparts.
Borg, Google’s internal server hosting infrastructure, is basically a simpler version of Kubernetes. It uses Infrastructure-as-Code to the extent that the configuration lives along-side the code in version control. But the configuration language is still quirky enough, and the production environment complex enough, that developers need to spend hours learning it. As soon as a project is big enough to have more than a handful of developers, these responsibilities are handed off to specialists.
With serverless functions, the Infrastructure really is as-Code, since it’s written in the same programming language as the business logic. There is virtually no learning curve for developers to deploy and monitor their code beyond fiddling with buttons in the UI. That time saved can instead be spent doing what really matters - providing value to your users. And unless infrastructure is your differentiator (video streaming, bitcoin mining etc), you probably do that by shipping features.

The gaps
- Cold Starts: If no instance is available to handle a request, you take a multi-second latency hit. The recently launched Google Cloud Functions (GCF) v2 has a concurrency feature to mitigate this, and other solutions are likely to follow.
- No asynchronous background work: You can’t perform clean-up work after responding to a web request. You need to do any book-keeping tasks synchronously before responding (latency impact), or use a trigger to schedule them out-of-band.
- No long-running tasks: AWS Lambda has a time limit of 15 minutes per execution, GCF v2 up to 60 minutes.
- Statelessness: Whether for rate-limiting, caching, or integrating with OpenTelemetry, valid use-cases for storing in-process state between requests do exist, and don’t work in a serverless context. As a result, serverless isn’t just a new hosting environment, it often requires a paradigm shift in systems design. Adjusting to this has been fun for me, and we will be sharing some of our solutions in follow-up posts.
Conclusion
Serverless may be a buzzword, but if you look beyond the marketing there are some real benefits to be had. There are still functionality and tooling gaps that will prevent many teams from making the switch at this stage. The teams that do, though, will be rewarded for being early by being able to move a little faster while spending a little less.
Wanna see some real speeed? We’re hiring! If any of this sounded interesting, check us out at https://throne.me or pop me an email at sam@throne.me.
